SchemaSmith Documentation

SchemaTongs Walkthrough
How to cast your first database with SchemaTongs
How to cast your first database with SchemaTongs
This guide provides a walkthrough for using SchemaTongs to extract an existing database schema into a repository suitable for source control, allowing modifications to be made.
To begin, ensure access to a running Microsoft SQL Server with an existing database from which to extract the schema. Authentication can be configured using either SQL Server Authentication or Windows Authentication, depending on the server setup. This tutorial uses a Docker container running a Linux SQL Server image on a Windows laptop, connecting via SQL Server Authentication.
This example involves two databases both extracted as part of a single test product.
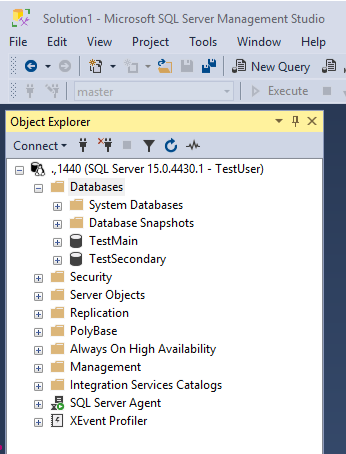
You can get the test product creation script here.
After installing SchemaTongs, configure the AppSettings.json file with the server, login details, and the first database to extract. Specify the directory for the new product and the names for the Product and Template. Renaming a template later is possible but cumbersome, as it affects both the template file and folder, as well as the product file. Below is an example of the edited AppSettings.json:
{
"Source": {
"Server": ", 1440",
"User": "TestUser",
"Password": "******************",
"Database": "TestMain"
},
"Product": {
"Path": "C:/Temp/Tutorial/TestProduct",
"Name": "TestProduct"
},
"Template": {
"Name": "TestMain"
},
"ShouldCast": {
"Tables": true,
"Schemas": true,
"UserDefinedTypes": true,
"UserDefinedFunctions": true,
"Views": true,
"StoredProcedures": true,
"TableTriggers": true,
"Catalogs": true,
"StopLists": true,
"DDLTriggers": true,
"XMLSchemaCollections": true,
"ScriptDynamicDependencyRemovalForFunctions": false,
"ObjectList": ""
}
}
The ShouldCast section allows customization to include or exclude specific object
types during extraction. For instance, setting a boolean to false omits that object
type. This allows for exporting a certain type of object again at some later point.
In scenarios with multiple production servers experiencing schema drift, one strategy is to extract each database from each environment, one by one, into separate folders. You can then compare differences among environments using a comparison tool to help decide what the final "gold" copy of the schema should be. This is important to examine before rolling out an upgrade using SchemaQuench as it will update every object every time and unplanned changes can have unexpected consequences when you are first bringing your environments into alignment.
If the specified product folder does not exist, then SchemaTongs will create it as part of the extraction. The tool will create a basic Product.json file the first time you extract to a given location. Later runs will update the product file to add any new templates but will not overwrite other values in the product.
When specified, ObjectList is a comma-delimited list of objects to include across
all the types you have enabled. If this is blank, then all objects will be included for the
enabled types.
This is a console application, so it is recommended that you run from a command prompt. The need to create directories may require the command prompt to be opened in Administrator mode.
The tool will output progress to the console window and also generate log files for progress and an error log with details about any errors encountered. A successful run should look something like this with more detail depending on how many objects exist in your database.
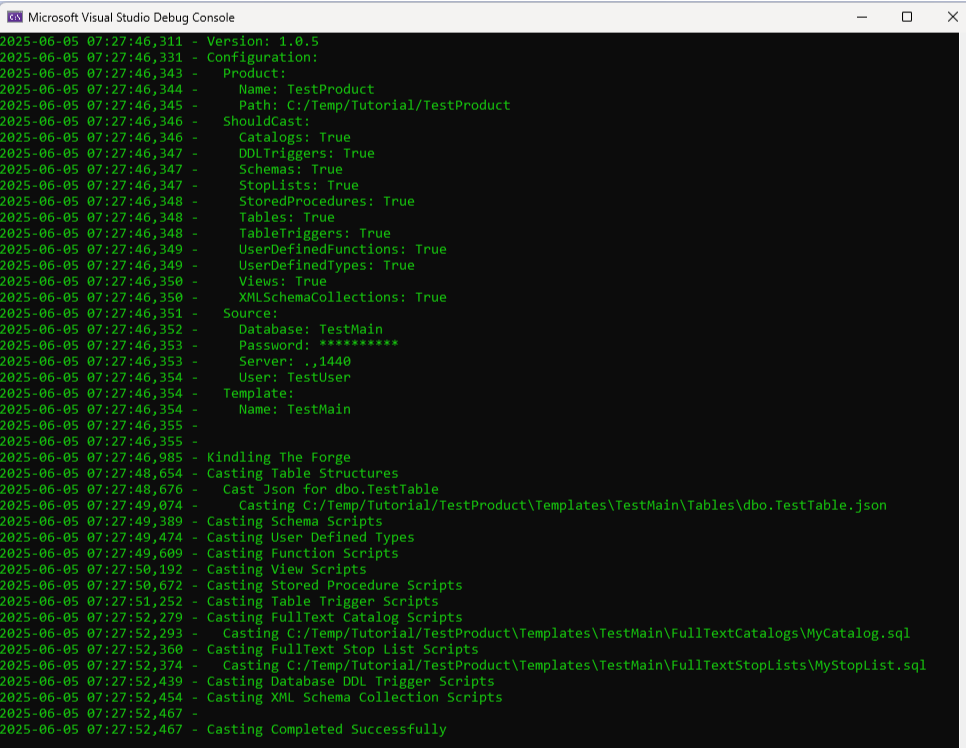
The progress log will contain the same text as the console window and gets backed up to a numbered folder between runs, if possible, in case you need to refer back to a prior run. Error messages will go into the errors log. The files and backup folders are produced in the folder containing SchemaTongs.
After the first run, you should have a Product.json file and a folder structure like this:
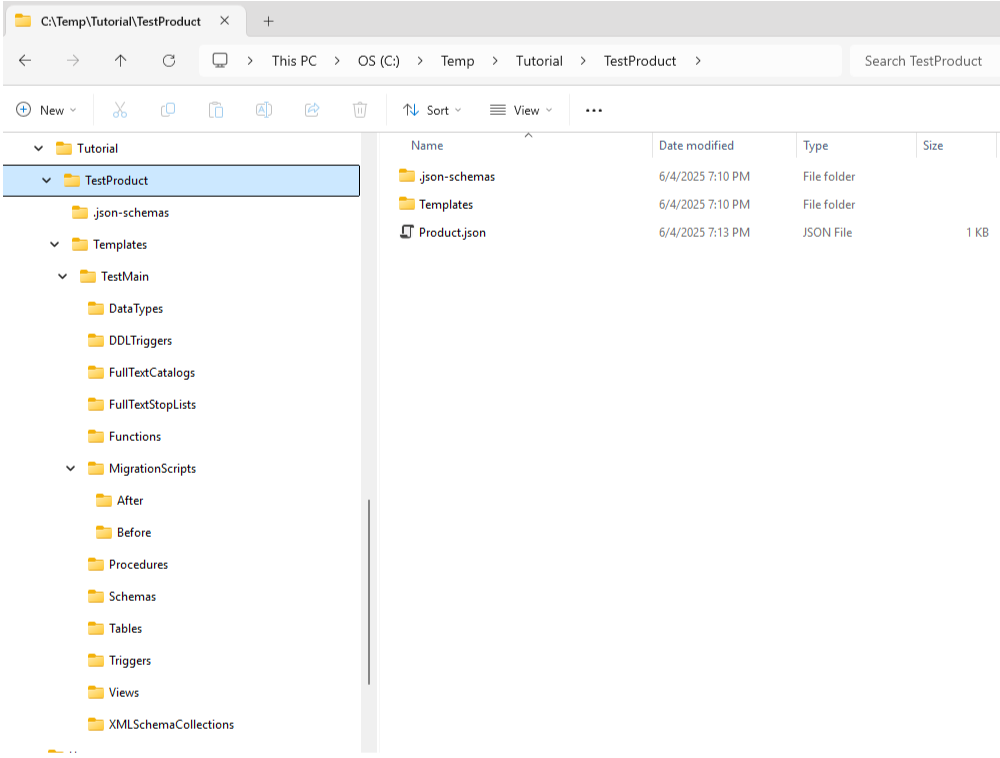
Many of the folders will be blank if you do not use those types of objects but this is the folder
structure that SchemaQuench supports. If you want to preserve the folders and your source control
does not support empty folders, you can put an empty text file, i.e., placeholder.txt, in each one
to force the structure to be maintained for later use. Either way, SchemaQuench will be fine. It
will expect either .json files (tables, product, and templates) or .sql files (for the scripted
objects) and anything else will be ignored. Missing folders are also ignored. In this case only
Tables, FullTextCatalogs, and FullTextStopLists contain
one file each, and the rest are empty.
The Product.json contains the following:
{
"Name": "TestProduct",
"ValidationScript": "SELECT CAST(CASE WHEN EXISTS(SELECT * FROM master.sys.databases WHERE [Name] = '{{TestMainDb}}') THEN 1 ELSE 0 END AS BIT",
"TemplateOrder": [
"TestMain"
],
"ScriptTokens": {
"TestMainDb": "TestMain"
}
}
For now, we assume that the product is valid if the database for the first extracted template exists.
However, you are free to add any conditions to the ValidationScript query to ensure you are running
against a valid server for the product. Notice the ScriptToken
TestMainDb for the database and its use in the ValidationScript. This allows
configuring for differences in the database name across deployed environments if needed.
The Template.json file contains:
{
"Name": "TestMain",
"DatabaseIdentificationScript": "SELECT [Name] FROM master.sys.databases WHERE [Name] = '{{TestMainDb}}'",
"UpdateFillFactor": true
}
The template has a DatabaseIdentificationScript which defaults to look for the name
we extracted from but this script can be modified to return any single database or list of databases
that you wish to match the template. Some products are one to one, and some have a mix of one-to-one and
many-to-one relationships between databases and templates. This gives you the flexibility to define
a single template that will automatically be used to update any or all matching databases on the
server with a single execution of SchemaQuench.
Update the AppSettings.json to point to the second database and run SchemaTongs a second time, with a new template name. The below snippet is showing just the keys that should be updated.
{
"Source": {
...
"Database": "TestSecondary"
},
...
"Template": {
"Name": "TestSecondary"
},
...
}
Now you should have a second template in your product with the same folder structure as the first:
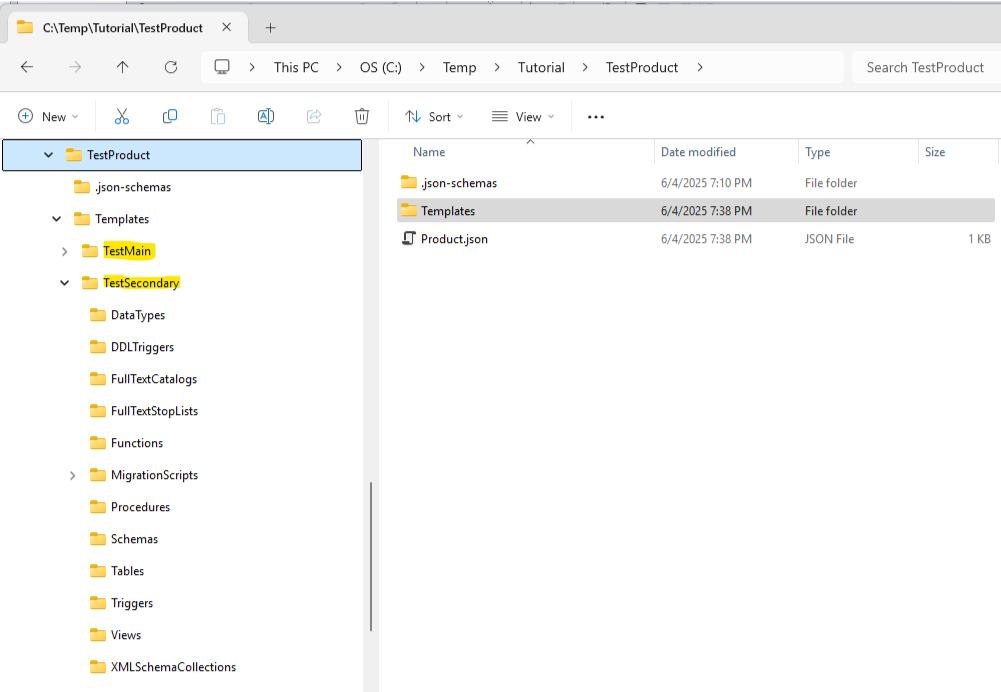
The Product.json now contains both templates, and we assume that the update order
is the same as the extraction order, though you are free to edit that. It also contains a new
script token for the new template which will be used in the DatabaseIdentificationScript.
{
"Name": "TestProduct",
"ValidationScript": "SELECT CAST(CASE WHEN EXISTS(SELECT * FROM master.sys.databases WHERE [Name] = '{{TestMainDb}}') THEN 1 ELSE 0 END AS BIT)",
"TemplateOrder": [
"TestMain",
"TestSecondary"
],
"ScriptTokens": {
"TestMainDb": "TestMain",
"TestSecondaryDb": "TestSecondary"
}
}
The new Template.json is identical to the first except for the script token used in
the DatabaseIdentificationScript property.
{
"Name": "TestSecondary",
"DatabaseIdentificationScript": "SELECT [Name] FROM master.sys.databases WHERE [Name] = '{{TestSecondaryDb}}'",
"UpdateFillFactor": true
}
You should now have a fully exported product that is ready to be quenched against a server of your choosing.
SchemaQuench is not intended to create missing databases, only to make the schema consistent
with existing ones. You can create an empty database, assuming your DatabaseIdentificationScript
is written to detect it, and SchemaQuench will create all the objects for you.